Issue:
Feature engineering is a critical part of machine learning, providing clean, high-quality, pre-calculated vectorized data. However, the challenge lies in dealing with various source types and applying the appropriate functions to each feature based on its type and requirements. I am exploring a more generic approach to handle all feature engineering tasks based on configuration, rather than relying on tedious manual work.
Assumptions:
1. Data Format:
• All data is stored in relational tables, either as key-value pairs converted from JSON or as columnar features.
2. Technology Stack:
• Using Spark with Databricks Clusters runtime 15.3 or above, due to its efficiency and speed compared to classic Pandas or Python, which are too slow for my tasks.
3. Environment:
• The environment has Unity Catalog enabled, but this should be optional and applicable to any Spark cluster.
4. Aggregation:
• Aggregation is performed on a daily basis, but it should be flexible enough to adjust to weekly or monthly aggregations.
How it works:
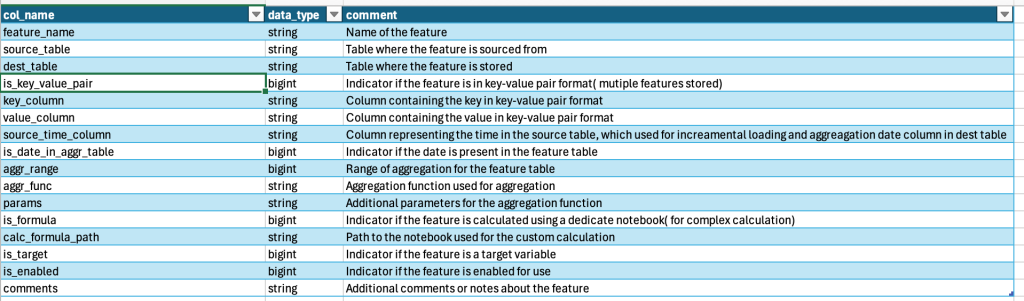
- Configuration Table Schema and its description.
- Process flow
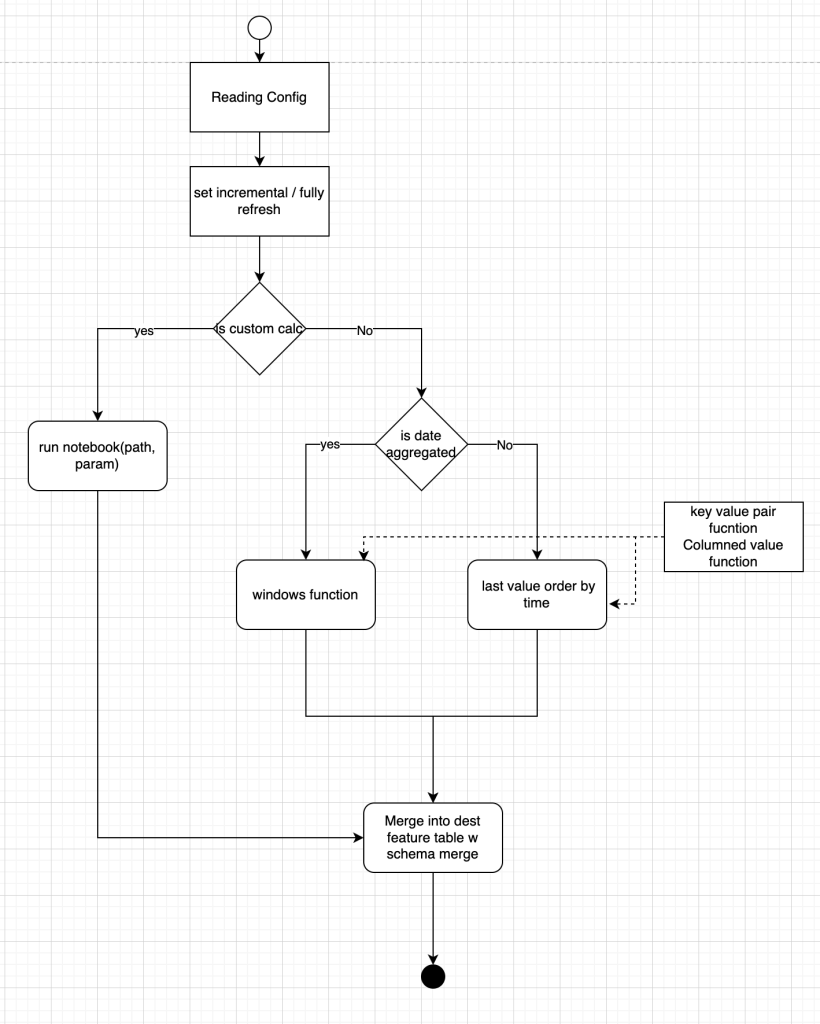
Key points
- Primary key & Time column. Setting up a primary key is crucial for downstream ML tasks. It enables us to join multiple feature tables and combine them with the target table for model training and validation. We use the “TIMESERIES” keyword to indicate a timestamp primary key. The “CLUSTER” keyword replaces the need for partitioning or z-ordering functions.
-- # CREATE or replace TABLE eus_prod.machinelearning.ft_device_aggr (
-- # cust_id int NOT NULL,
-- # `date` date NOT NULL,
-- # device_id integer,
-- # CONSTRAINT pk_ft_device_message_aggr PRIMARY KEY (cust_id,device_id,date TIMESERIES))
-- # CLUSTER BY (cust_id,date);- Merge and schema evolution. Merge and schema evolution are streamlined as more features are added to the destination table. There is no need to alter the feature table before processing. The following code handles new features efficiently, provided it runs on Databricks runtime 15.3 or above.
MERGE WITH SCHEMA EVOLUTION INTO {dest_table} AS target
USING df_feature AS source
ON source.cust_id = target.cust_id AND source.device_id = target.device_id
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *- Function. All window functions supported by the configuration table can be utilized. Alternatively, we can design our own Pandas UDF and apply it to a series of data based on a specified time window. Below is an example of calculating the slope over a rolling X-day window.
@pandas_udf(DoubleType())
def calc_slope(day_rank: pd.Series, sales: pd.Series) -> float:
N = len(day_rank)
sum_x = day_rank.sum()
sum_y = sales.sum()
sum_xy = (day_rank * sales).sum()
sum_x2 = (day_rank * day_rank).sum()
slope = (N * sum_xy - sum_x * sum_y) / (N * sum_x2 - sum_x ** 2)
return slope
# Register the UDF
spark.udf.register("calc_slope", calc_slope)- Parameters in Configuration. We can set up various parameter formats in the “params” column of the configuration table. These parameters can then be passed into either a custom notebook or your generic SQL model. Here I leverage “param_list” as a list of parameters and pass it to notebook.
dbutils.notebook.run("./"+calc_formular_path, 1800,{"back_days":day_back_num,"cust_ids":cust_list,"param_list":param_list})TBD Improvement:
- Feature Dependencies:In the current version, we calculate all features sequentially based on their order in the configuration table. However, we should add a dependency column to indicate the relationships between multiple features.
- Scaling and Normalization:Currently, we perform scaling and normalization on-the-fly in the ML notebook during runtime. However, incorporating these steps into the pre-aggregation phase via configuration should be straightforward.
- Bag of Words/Text Processing:All calculations are currently based on time-series data. There may be differences when dealing with natural language feature engineering.
- Handling Missing Values and Outliers:We should enable a separate model to check and correct missing values or eliminate outlier data.
Leave a Reply