Dr.Kazuaki Ishizaki gives a great summary of spark 3.0 features in his presentation “SQL Performance Improvements at a Glance in Apache Spark 3.0” . It is very helpful for us to understand how these new features work and where we can use it.
New explain format
Spark 3.0 provides a terse format explain with detail information.
EXPLAIN [ EXTENDED | CODEGEN | COST | FORMATTED ] statementThere are five formats:
- default. Physical plan only.
- extended. It equals df.explain(true) in spark 2.4, which generates parsed logical plan, analyzed logical plan , optimized logical plan and physical plan.
- codegen. Generates java code for the statement.
- code. If plan stats are available, it generates a logical plan and the states.
- formatted. This is most useful in my mind. It has two sections, a physical plan outline with simple tree format and node details.
-- example from spark document
-- Using Formatted
EXPLAIN FORMATTED select k, sum(v) from values (1, 2), (1, 3) t(k, v) group by k;
+----------------------------------------------------+
| plan|
+----------------------------------------------------+
| == Physical Plan ==
* HashAggregate (4)
+- Exchange (3)
+- * HashAggregate (2)
+- * LocalTableScan (1)
(1) LocalTableScan [codegen id : 1]
Output: [k#19, v#20]
(2) HashAggregate [codegen id : 1]
Input: [k#19, v#20]
(3) Exchange
Input: [k#19, sum#24L]
(4) HashAggregate [codegen id : 2]
Input: [k#19, sum#24L]
|
+----------------------------------------------------+As these syntax are not exactly match with spark, the following list is help to explain the “meaning of spark explain”
- scan. Basic file access. In spark 3.0, it can achieve some predication tasks before load data in.
- ColumnPruning: select the columns only needed.
- Partitionfilters: only grab data from certain partitions
- Pushedfilters: filter fields that can be directly to file scan(push down prediction)
- filter. Due to pushdown prediction, lots of filter work has moved to scan stage, so you may not find filter in explain matching with query. But there are still some operations like first, last, we need to do it in filter.
- Pushdown prediction.
- Combine filters: combines two neighboring operations into one
- Infer filter from constraints. create a new filter form a join condition. we will talk about it in next section “dynamic partitioning pruning”.
- prune filter.
- project. Select operation for columns, like select, drop, withColumn.
- exchange. shuffle operation, like sortmerge, shuffle hash
- HashAggregate. data aggregation.
- BroadcastHashJoin & broadcastExchange. Broadcast shuffle.
- columnarToRow. a transition between columnar and row execution.
All type of Join hints
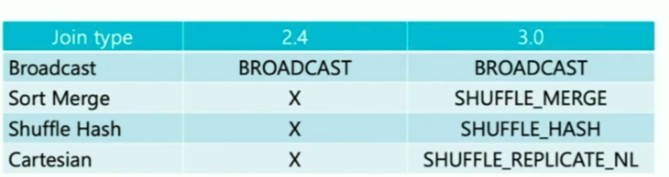
Spark uses two types of hints, one is partition hints, other is join hints. Since spark 3.0, join hints support all type of join.
- Broadcast join. which is famous join for joining small table(dimension table) with big table(fact table) by avoiding costly data shuffling.
- table less than 10MB is broadcast across all nodes to avoid shuffling
- two steps: broadcast –> hash join
- spark.sql.autoBroadcastJoinThreshold
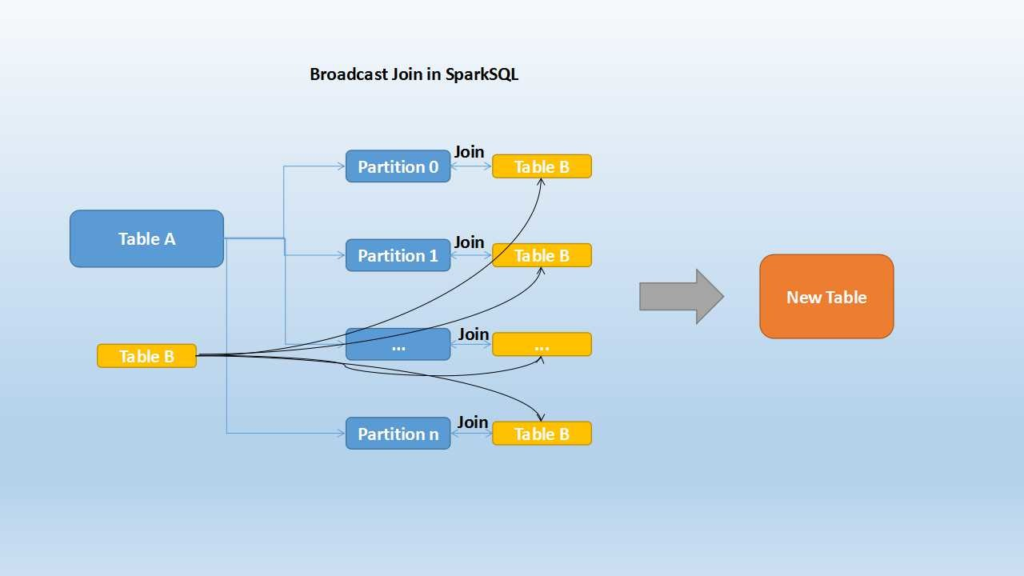
- shuffle merge join
- Sort merge join perform the Sort operation first and then merges the datasets.
- steps:
- shuffle. 2 big tables are partitioned as per the join keys across the partitions.
- sort. sort the data within each partition
- merge. join the 2 sorted and partitioned data.
- work well when
- two big tables as it doesn’t need load all data into memory like hash join
- highly scalable approach
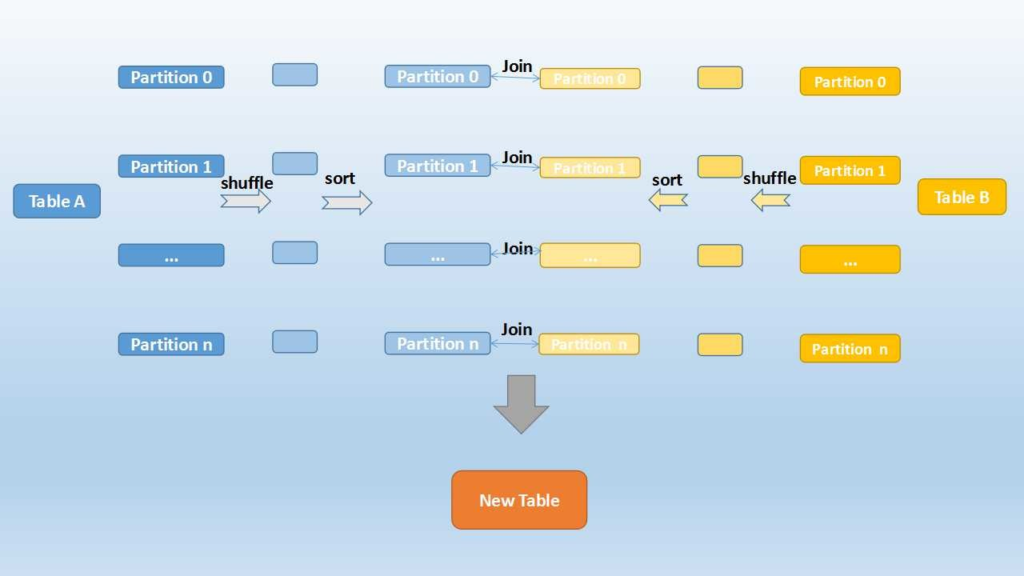
- shuffle hash join
- Shuffle hash join shuffles the data based on join key, so that rows related to same keys from both tables will be moved on to same node and then perform the join.
- works well when
- dataframes are distributed evenly with the keys
- dataframes has enough number of keys for parallelism
- memory is enough for hash join
- supported for all join except full outer join
- spark.sql.join.preferSortMergeJoin = false
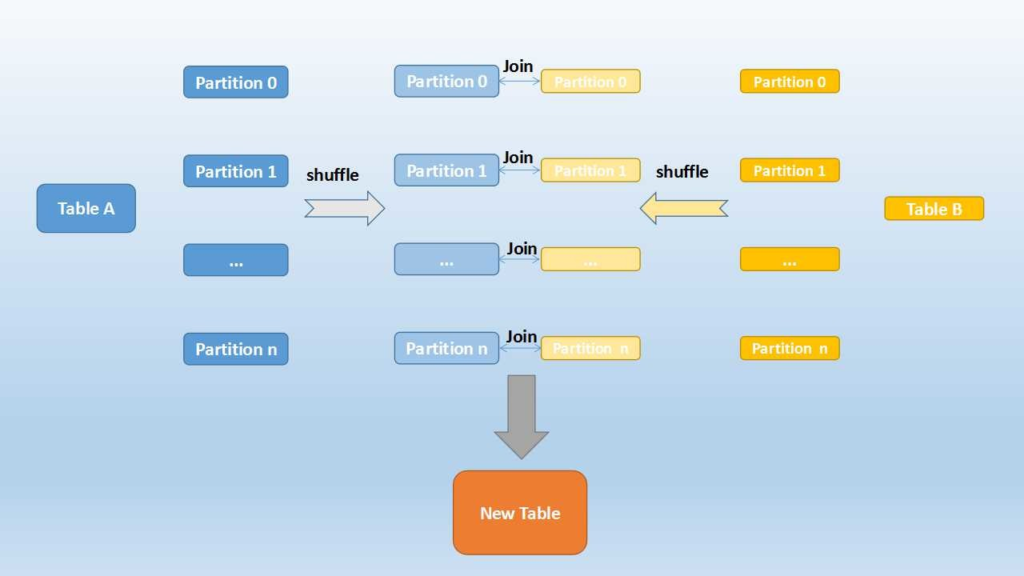
- shuffle replicate nl
- cartesian product(similar to SQL) of the two relations is calculated to evaluate join.
Adaptive query execution(AQE)
AQE is automatic feature enabled for strategy choose in the running time.
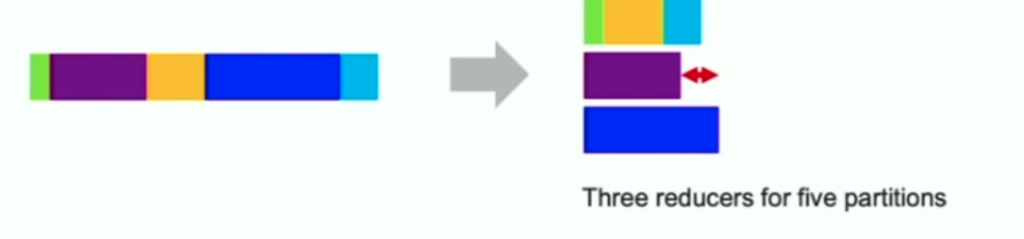
- Set the number of reducers to avoid wasting memory and I/O resource. Dynamically coalescing shuffle partitions.
- spark.sql.adaptive.enabled=true
- spark.sql.adaptive.coalescePartitions.enabled=ture
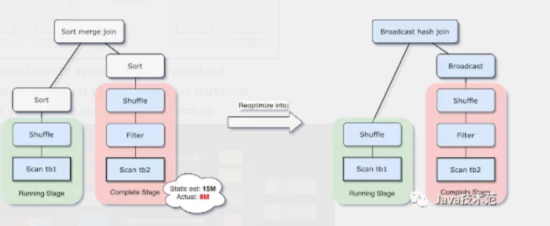
- select better join strategy to improve performance
- dynamically choose from 3 join strategy. broadcast has best performance, but static strategy choose is not accurate sometimes.
- spark.sql.adaptive.enabled=true
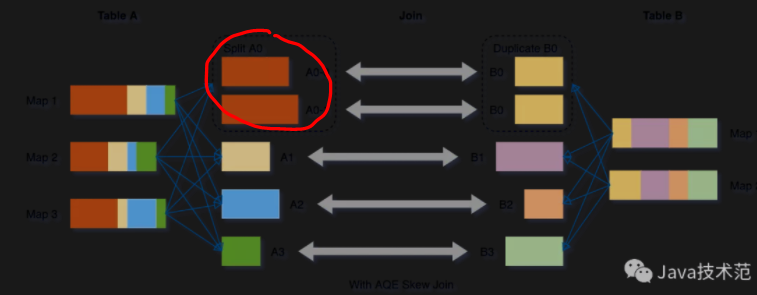
- Optimize skewed join to avoid imbalance workload
- the large partition is split into multiple partitions
- spark.sql.adaptive.skewJoin.enabled=true
Dynamic partitioning pruning
We already peek part of it in explain format. Spark 3.0 is smart that avoid to read unnecessary partitions in a join operations by using results of filter operations in another table. for example,
SELECT * FROM dim_iteblog
JOIN fact_iteblog
ON (dim_iteblog.partcol = fact_iteblog.partcol)
WHERE dim_iteblog.othercol > 10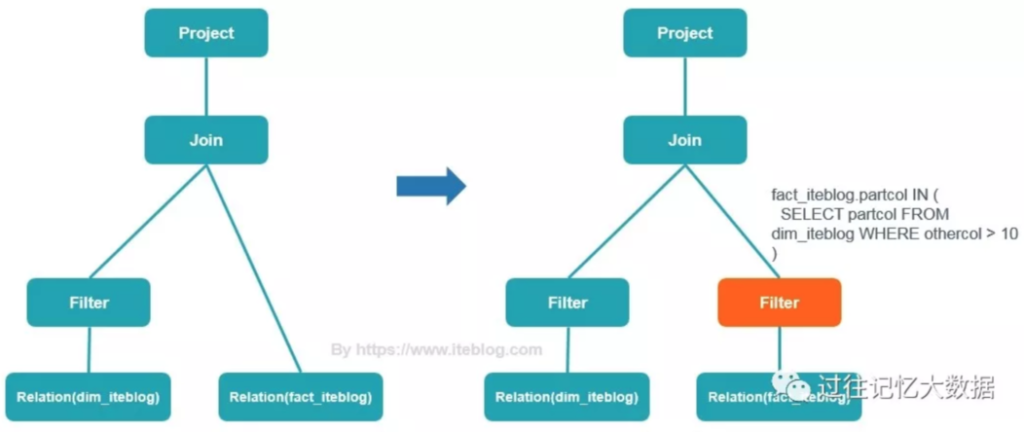
In this case, spark will do the prune prediction and add a new filter for join table “fact_iteblog”.
Enhanced nested column pruning & pushdown
- nested column pruning can be applied to all operators, like limits, repartition
- select col2._1 from(select col2 from tp limit1000)
- parquet can apply pushdown filter and can read part of columns
- spark.read.parquet(‘filename’).filter(‘col2._1 = 100’)
Improved aggregation code generation
- Catalyst translates a given query to java code, Hotspot compiler in OpenJDK translates Java code into native code
- HotSpot compiler gives up generating native code for more than 8000 Java bytecode instruction per method.
- Catalyst splits a large java method into small ones to allow hotspoot to generate native code

New Scala and Java (infrastructure updates)
- Java 11
- Scala 2.12
Summary
I think it is better to take a screenshot from presentation of Dr.Kazuaki Ishizaki to do the summary.

Reference
SQL Performance Improvements at a Glance in Apache Spark 3.0, https://www.iteblog.com/ppt/sparkaisummit-north-america-2020-iteblog/sql-performance-improvements-at-a-glance-in-apache-spark-30-iteblog.com.pdf
Spark 3.0.1 – Explain, http://spark.apache.org/docs/latest/sql-ref-syntax-qry-explain.html
Mastering Query Plans in Spark 3.0, https://towardsdatascience.com/mastering-query-plans-in-spark-3-0-f4c334663aa4
Fast Filtering with Spark PartitionFilters and PushedFilters, https://mungingdata.com/apache-spark/partition-filters-pushed-filters/
Spark 3.0.1 – Hints, https://spark.apache.org/docs/3.0.0/sql-ref-syntax-qry-select-hints.html